Cocos Shader 基础入门(二):顶点着色器与片元着色器
本文转自Cocos官方论坛 https://forum.cocos.org/t/topic/123751
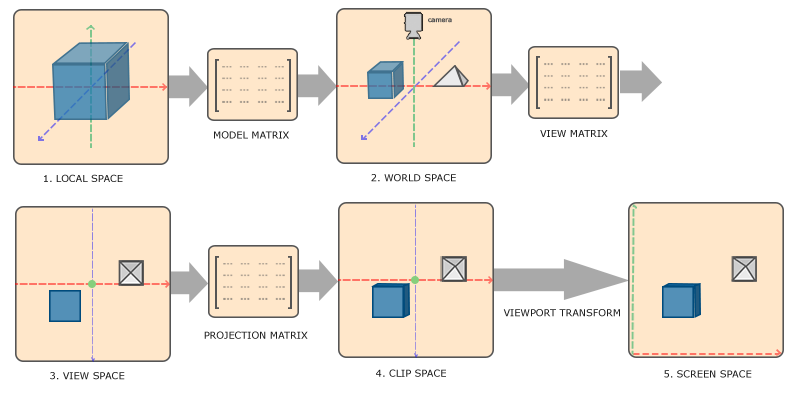
在上一章中介绍了 WebGL 的一些基础概念。总结起来就两句话,WebGL 在 GPU 上的工作基本上分为两部分, 第一部分是将顶点数据转换到裁剪空间坐标, 第二部分是基于第一部分的结果绘制像素点。
本章重点来了解一下 顶点着色器和片元着色器在渲染管线流程中的作用 。我们就以 “渲染一个三角形 ”为例,了解一下这其中涉及到的渲染知识。
顶点输入
与标准化设备坐标
在我们开始绘制图形之前,必须先给 WebGL 输入一些顶点数据。假如我们希望渲染一个平面三角形,就需要指定三个顶点,每个顶点都有一个二维位置,以数组的形式存储。
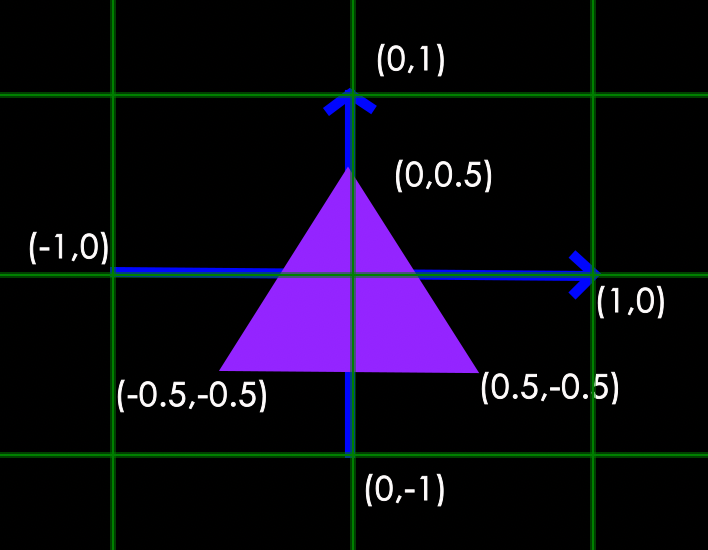
var positions = [0, 0,0, 0.5,0.7, 0,];// 因为是平面三角形,所以没有深度(z)
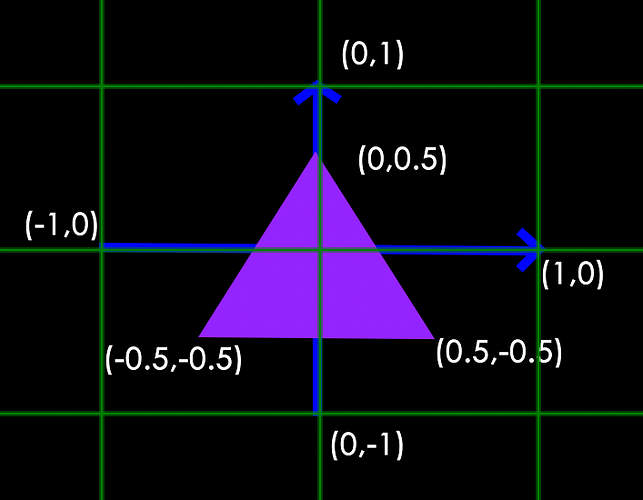
此处,为什么用这样的数值,也是有讲究。在上一个章节也说过,顶点着色器主要功能是坐标转换,把顶点坐标转换到裁剪坐标,这一步是我们可以控制的。接着再由 GPU 通过裁剪与透视剔除法处理后得到 标准化设备坐标(Normalized Device Coordinates,NDC) 。透视除法通过将裁剪空间里顶点的 3 个分量都除以 w 分量,实现裁剪坐标转换到 NDC。NDC 的每一个分量值都在 -1~1 之间,超出部分最终就不会呈现。因此,在游戏引擎里无论使用的是局部坐标或者世界坐标也,都需要经过坐标转换。最终,GPU 会将 NDC 转换成屏幕坐标传入光栅器。因为本章重点讲述渲染流程,因此,不采用游戏内常用的局部坐标,而是直接使用裁剪坐标。
下图是用 NDC 绘制的三角形(忽略 z 轴):
编写渲染代码
有了这样一组顶点数据之后,就可以将它作为输入,发送给图形渲染管线的第一个阶段:顶点着色器。它会在 GPU 上创建内存用于存储顶点数据,接着,再结合顶点组合方式解析这些内存。WebGL 通过顶点缓冲对象(VBO)管理这个内存,它会在 GPU 内存(显存)中存储大量顶点,供顶点着色器使用。接下来,我们试着将顶点数据提交到 GPU。
<body>// 如果是用 chrome 等浏览器进行测试独立的 html 文件的,需要运行脚本,否则不用加下面这句<script src="./shader.js"></script></body>// js"use strict";// 从 main 函数开始看// 创建着色器 shader。gl:WebGL 上下文;type:着色器类型;source:着色器文本function createShader(gl, type, source) {// 根据 type 创建着色器var shader = gl.createShader(type);// 绑定内容文本 sourcegl.shaderSource(shader, source);// 编译着色器(将文本内容转换成着色器)gl.compileShader(shader);// 获取编译后的状态var success = gl.getShaderParameter(shader, gl.COMPILE_STATUS);if (success) {return shader;}// 获取当前着色器相关信息console.log(gl.getShaderInfoLog(shader));// 删除失败的着色器gl.deleteShader(shader);}// 创建着色程序 program。gl:WebGL 上下文;vertexShader:顶点着色器对象;fragmentShader:片元着色器对象function createProgram(gl, vertexShader, fragmentShader) {// 创建着色程序var program = gl.createProgram();// 让着色程序获取到顶点着色器gl.attachShader(program, vertexShader);// 让着色程序获取到片元着色器gl.attachShader(program, fragmentShader);// 将两个着色器与着色程序进行绑定gl.linkProgram(program);var success = gl.getProgramParameter(program, gl.LINK_STATUS);if (success) {return program;}console.log(gl.getProgramInfoLog(program));// 绑定失败则删除着色程序gl.deleteProgram(program);}function main() {// 步骤一:获取 gl// 创建画布const canvas = document.createElement('canvas');document.getElementsByTagName('body')[0].appendChild(canvas);canvas.width = 400;canvas.height = 300;// 获取 WebGL 上下文(Context),后续统称 gl。const gl = canvas.getContext("webgl");if (!gl) {return;}// 步骤二:顶点着色器// 定义顶点着色器文本const vertexShaderSource = `// 接收顶点位置数据attribute vec2 a_position;// 着色器入口函数void main() {// gl_Position 接收的就是一个 vec4,因此需要转换gl_Position = vec4(a_position, 0.0, 1.0);}`;// 根据着色器文本内容,创建 WebGL 上可以使用的着色器对象const vertexShader = createShader(gl, gl.VERTEX_SHADER, vertexShaderSource);// 自定义裁剪坐标。还是以画三角形为例提供顶点数据。因为是一个平面三角形,因此每一个顶点只提供一个 vec2 即可。const positions = [0, 0,0, 0.5,0.7, 0,];// 创建顶点缓冲对象const vertexBuffer = gl.createBuffer();// 将顶点缓冲对象绑定到 gl 的 ARRAY_BUFFER 字段上。gl.bindBuffer(gl.ARRAY_BUFFER, vertexBuffer);// 通过 bufferData 将当前顶点数据存入缓冲(vertexBuffer)中// 之前有说过,gl 内部有很多默认状态,所以此时需要明确储存的顶点缓冲是我自定义的缓冲。在 GPU 中数据存储需要很谨慎,不然就有可能造成内存浪费。// 接着,需要明确数据大小,这里顶点坐标的每一个分量都采用 32 位浮点型数据存储。需要合理的为每一类型数据分配内存。// 最后一个参数 gl.STATIC_DRAW 是提示 WebGL 我们将怎么使用这些数据。因为此处我们将顶点数据写死了,所以采用 gl.STATIC_DRAW。// gl.STATIC_DRAW :数据不会或几乎不会改变。// gl.DYNAMIC_DRAW:数据会被改变很多。// gl.STREAM_DRAW :数据每次绘制时都会改变gl.bufferData(gl.ARRAY_BUFFER, new Float32Array(positions), gl.STATIC_DRAW);// 步骤三:片元着色器// 同顶点着色器操作类似// 获取片元着色器文本const fragmentShaderSource = `precision mediump float;// 着色器入口函数void main() {// 将三角形输出的最终颜色固定为玫红色// 这里的四个分量分别代表红(r)、绿(g)、蓝(b)和透明度(alpha)// 颜色数值取归一化值。最终绘制的其实就是 [255, 0, 127. 255]gl_FragColor = vec4(1, 0, 0.5, 1);}`;const fragmentShader = createShader(gl, gl.FRAGMENT_SHADER, fragmentShaderSource);// 步骤四:着色程序// 将顶点着色器和片元着色器绑定到着色程序上。// 这个上一章提过,着色程序需要成对提供,其中一个是顶点着色器,另一个是片元着色器const program = createProgram(gl, vertexShader, fragmentShader);}// 此处可以直接上 WebGL 中文网上练习,https://webglfundamentals.org/webgl/lessons/zh_cn/webgl-fundamentals.html。此时我们已经把输入顶点数据发送给了 GPU,并指示了 GPU 如何在顶点着色器中处理它。但此时,WebGL 还不知道它该如何解释内存中的顶点数据、以及它该如何将顶点数据链接到顶点着色器的属性上。我们需要告诉 WebGL 怎么做。
注意:使用 “vertexBuffer” 缓冲对象的好处是可以一次性发送一大批数据到显卡上,而不是每个顶点发送一次。从 CPU 把数据发送到显卡相对较慢,所以只要可能都要尝试尽量一次性发送尽可能多的数据。当数据发送至显卡的内存中后,顶点着色器几乎能立即访问顶点,这个过程非常快。
顶点数据解析
顶点着色器允许指定任何以顶点属性为形式的输入,即一个顶点可以包含多个属性。这种形式的输入为我们在数据组织上提供很大的灵活性。一个 float 32 位的顶点缓冲数据会被解析为如下的样子:
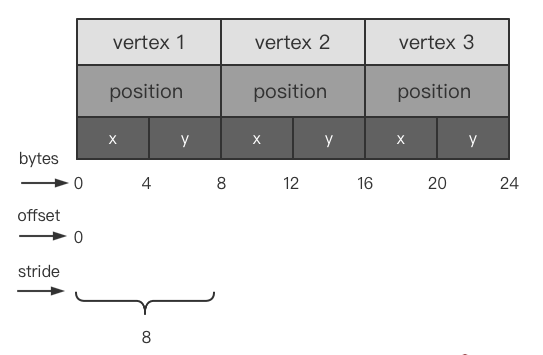
这是一个最基础的顶点缓冲数据的结构,只由 position 数据填充。其中:
每个顶点位置包含 2 个位置分量。由于缓冲采用的是 float 32 位浮点数型数组,一个字节是 8 位,因此这里每个顶点的分量按字节划分它们之间的差值是 4 个字节。
offset 代表当前输入数据在 一个顶点数据里 的偏移。由于这个顶点数据里只有 position,因此偏移量为 0。如果后续还有顶点颜色,纹理坐标等,那么就需要根据数据结构,选取合适的偏移量,偏移量采用“数据偏移长度 x 字节数的形式提供”。
stride 代表一个顶点数据总的字节长度,计算方式为 顶点数据长度 * sizeof(float) 。比如:一个 position 有 2 个分量,采用的是 float 32 位浮点型数据,那么它所占用的字节数为 2x4 = 8。
了解了这些之后,接着,继续着色的内容:
`

注意:此处为了便于观察,将 clearColor 的颜色清除成了黑色,因此背景呈现黑色。
可以看到,我们成功的绘制出了一个三角形,到此,已经完成了渲染的第一步,正式的迈入了这个门槛。在下一章会对本章的内容继续做一些补充,加深对本章内容的巩固。
内容参考:
视频讲解>>
所有文章转载、摘编或复制时,需注明出处,违者必究!
举报邮箱:eexporter@163.com
推荐阅读